Speech Emotion
Recognition
Qingyuan Kong
Problem
I want to make the computer
automatically recognize the emotion in the speech, such like fear, angry,
happiness. The recognition is based on voice not text.
Method
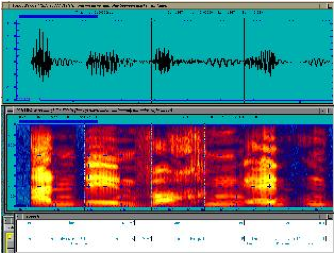
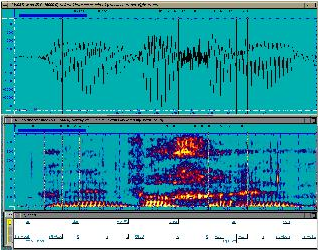
There are different patterns
underlying the STFT (short-time Fourier transform) representation of the
speech, see Figure 1 and 2 (The figures and sound files are from http://database.syntheticspeech.de/).
Suppose the STFT representation of a piece of speech is A, which is a F*T matrix, it can be decomposed into N components (N is
to be decided by the specified algorithm), A=W*Z*H, where W is a F*N matrix, Z
is a N*N diagonal matrix, and H is a N*T matrix. The ith
column of W is the distribution in frequency domain of the ith
component; the ith row of H is the distribution in time
domain of the ith component; the ith
diagonal element of Z is weight of the ith component. In this step, the source separation
algorithm proposed in Reference1 will be used. I will find similar components
in frequency domain across all the speeches of the same emotion. Then for each
emotion e,
I will have a component set Se. Then for each input unknown speech, I will find
which set the components of the speech come from mostly, then
the speech will be recognized as that emotion. For this step, the EM algorithm
proposed in Reference 2 will be used.
Dataset
I will use “a database of
German emotional speech”, which contains 800 sentences (7 emotions * 10 actors
* 10 sentences + some second versions). The link for the dataset is http://database.syntheticspeech.de/
Accomplishment
by the milestone
By the milestone, I will
have implemented most of the algorithms and had a primary result.
Reference
1 Paris Smaragdis,
Bhiksha Raj, “Shift-Invariant Probabilistic
Latent Component Analysis”,
TR2007-009, December 2007
2 MVS Shashanka,
Latent Variable Framework for Modeling and Separating Single Channel Acoustic Sources,
Department of Cognitive and Neural Systems, Boston University, August 2007